为了能够在广泛的现实世界动态环境中部署,机器人应该能够成功完成各种手动任务,从家务到复杂的制造或农业过程。这些手动任务需要抓取、纵和放置不同类型的物体,这些物体的形状、重量、属性和纹理可能各不相同。
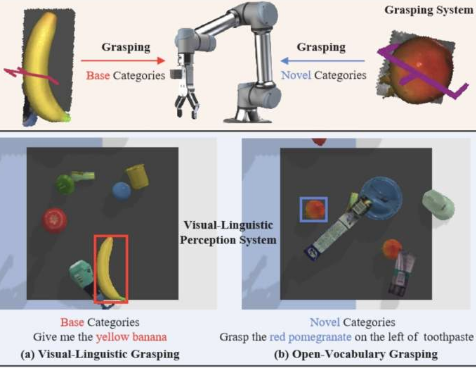
然而,目前大多数实现机器人抓取和纵物体的方法仅允许机器人成功与与训练期间遇到的物体匹配或非常相似的物体进行交互。这意味着当它们遇到一种新类型的物体(即以前从未见过的物体)时,许多机器人无法抓住它。
北京航空航天大学和利物浦大学的一组研究人员最近着手开发一种新方法,以克服机器人抓取系统的这一关键限制。他们的论文发布在arXiv预印本服务器上,介绍了OVGNet,这是一个统一的视觉语言框架,可以实现开放词汇学习,从而使机器人能够抓取已知和新类别的物体。
“识别和抓取新类别的物体仍然是现实世界机器人应用中一个关键而又具有挑战性的问题,”李猛、赵奇和他们的同事在论文中写道。“尽管它意义重大,但在这一特定领域的研究却很有限。
“为了解决这个问题,我们无缝地提出了一个新颖的框架,将开放词汇学习整合到机器人抓取领域,使机器人能够熟练地处理新物体。”
研究人员的框架依赖于他们编制的一个名为OVGrasping的新基准数据集。该数据集包含63,385个抓取场景示例,其中的物体属于117个不同的类别,分为基础(即已知)和新(即未见过)类别。
“首先,我们提出了一个大型基准数据集,专门用于评估开放词汇抓取任务的性能,”李、赵和他们的同事写道。“其次,我们提出了一个统一的视觉语言框架,作为机器人成功抓取基本物体和新物体的指南。第三,我们引入了两个对齐模块,旨在增强机器人抓取过程中的视觉语言感知。”
OVGNet是该研究团队推出的新框架,它基于视觉语言感知系统,该系统经过训练可以识别物体并设计出有效的策略,利用视觉和语言元素来抓取物体。该框架包括图像引导语言注意模块(IGLA)和语言引导注意模块(LGIA)。
这两个模块共同分析检测到的物体的整体特征,增强了机器人在已知和新物体类别中概括其抓取策略的能力。
研究人员在基于pybullet的抓取模拟环境中进行了一系列测试,使用模拟的ROBOTIQ-85机器人和UR5机械臂,评估了他们提出的框架。他们的框架取得了令人鼓舞的结果,在涉及新物体类别的任务中,其表现优于其他机器人抓取基准方法。
李、赵和他们的同事写道:“值得注意的是,我们的框架在新的数据集中对基础和新颖类别的平均准确率分别达到了71.2%和.4%。”
研究人员编制的OVGrasping数据集及其OVGNet框架代码都是开源的,其他开发人员可以在GitHub上访问。未来,他们的数据集可用于训练其他算法,而他们的框架可以在其他实验中进行测试并部署在其他机器人系统上。
标签:
免责声明:本文由用户上传,如有侵权请联系删除!